はじめに #
ウェブUIのテストツールであるseleniumを使った、ブラウザ操作の自動化についてまとめた。 seleniumはウェブUIのテストを自動化するためのツールである。これをPythonから呼び出すことで、ウェブ画面上の操作を自動化できる。
本記事では、環境構築 (seleniumとWebDriverの準備)と、ウェブページの自動操作について述べる。
環境は以下の通り。
| バージョン | |
|---|---|
| Python | 3.7.3 |
| selenium | 3.141.0 |
また、OSはWindows 8.1である。
環境構築 #
seleniumのインストールと、WebDriverのダウンロードを行う。 conda環境では、seleniumを以下の通りインストールする。
conda install selenium
それ以外では、pipでインストールする。
conda install selenium
次にWebDriverをダウンロードする。WebDriverはブラウザごとに異なるものが必要になる。 2020年12月17日現在、ChromeのWebDriverは以下のページからダウンロードできる。
Downloads - ChromeDriver - WebDriver for Chrome
上記のページから、Chromeのバージョンや、OSが一致するWebDriverをダウンロードする。 ダウンロードしたzipファイルを展開するとchromedriver.exeという実行ファイルがあるので、適当なフォルダに置く。 本記事では、以下のパスに置くこととする。
C:\selenium\chromedriver.exe
chromedriver.exeにパスを通しておくと後々便利であるが、ここではパスを通さずに進める。
ただし、記事を読まれている時点では、WebDriverの情報は古くなっている可能性があるため、適宜最新の情報を参照されたい。最新の情報や、他のブラウザのダウンロード方法については、「selenium WebDriver (ブラウザ名)」で検索すると出てくる。
seleniumによるページ制御の基本 #
以下の手順により、Pythonでseleniumを使ったページ制御を行う。
- WebDriverでブラウザを起動
get()メソッドでページを取得find_*メソッドでWebElementオブジェクト(ページの要素)を取得- WebElementオブジェクトのメソッドを使ってページを操作する
ウェブページを開く #
以下のスクリプトを実行すると、英語版Wikipediaのトップページが開く。
例1
from selenium import webdriver
driver = webdriver.Chrome(executable_path="C:\selenium\chromedriver.exe")
driver.get("https://en.wikipedia.org")
まず、webdriver.Chromeでブラウザを立ち上げ、WebDriverオブジェクトを取得する。使用するブラウザによって、Chromeの部分を適宜変更する。また、executable_pathでWebDriverを指定するが、chromedriver.exeにパスが通っている場合は指定する必要はない。
次に、WebDriverオブジェクトのget()メソッドに開きたいURLを渡すと、ページを開く。
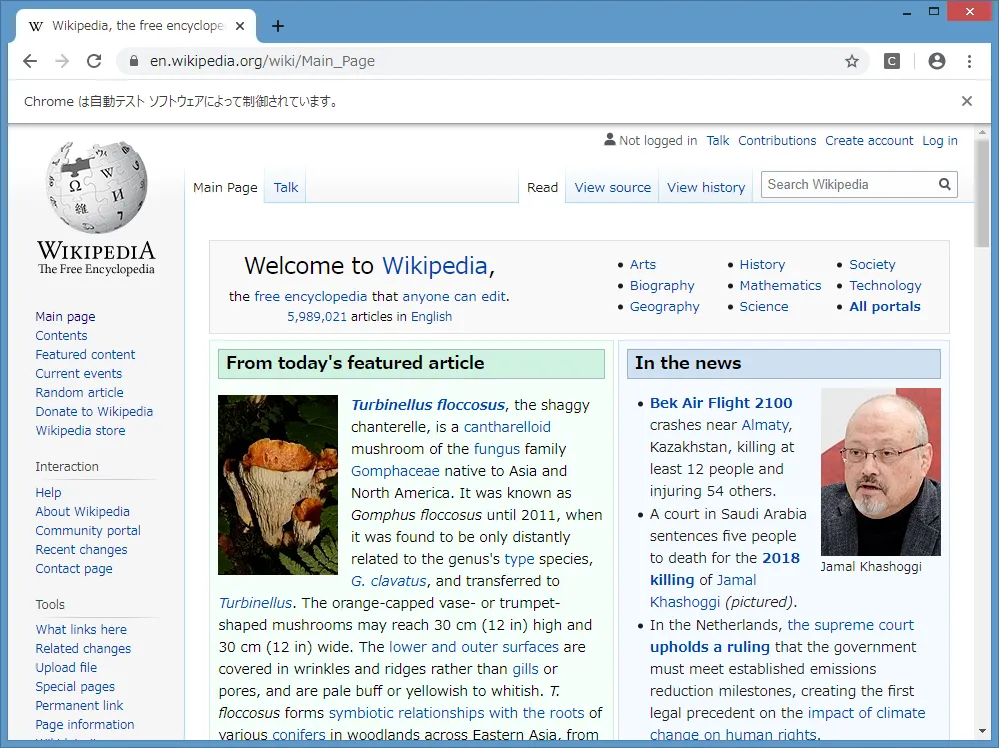
なお、ブラウザを閉じるときは、WebDriverオブジェクトのquit()メソッドを実行する。
ウェブページの要素を探す #
WebDriverのメソッドを使って、操作したい要素を探す。
メソッドは大きく分けて2種類あり、検索条件に一致する最初の要素をWebElementオブジェクトとして返すものと、検索条件に一致する全ての要素をWebElementオブジェクトのリストとして返すものがある。
前者はfind_element_から始まる名前のメソッドであり、後者は複数形のfind_elements_から始まる名前のメソッドである。
find_element_から始まる主なメソッドを以下に示す。
| メソッド | 内容 |
|---|---|
find_element_by_id |
id属性が一致する要素 |
find_element_by_name |
name属性が一致する要素 |
find_element_by_link_text |
完全一致する<a>要素 |
find_element_by_partial_link_text |
部分一致する<a>要素 |
find_element_by_tag_name |
タグ名と一致する要素 |
find_element_by_class_name |
CSSクラスと一致する要素 |
find_element_by_css_selector |
CSSセレクタに一致する要素 |
これらのelementをelementsに置き換えると、全ての要素を検索できる。
例2 以下のHTMLがあったとする。
<a href="https://en.wikipedia.org">Wiki</a>
このHTMLをブラウザで開くと、https://en.wikipedia.orgへリンクを張った、Wikiという文字列が表示される。
また、上記の例では、HTMLの各構造は以下の名前で呼ばれる。
a: タグ名href: 属性Wiki: 内部テキスト
ここで、<a>の開始タグと終了タグで囲まれた全体を要素と呼ぶ。
この要素をSeleniumで探すには、
WebDriver.find_element_by_link_text("Wiki")
または、
WebDriver.find_element_by_tag_name("a")
のようにする。
要素の内容を取得する #
WebElementオブジェクトには、要素の内容を取得するために、以下のような属性やメソッドがある。
| 属性・メソッド | 内容 |
|---|---|
tag_name |
タグ名 |
text |
要素の内部テキスト |
get_attribute(name) |
name属性の値 |
ウェブページを操作する #
クリックする #
WebElementオブジェクトのclick()メソッドを実行すると、その要素上でマウスをクリックする。
例3
例1で開いたWikipediaの左カラム上部にある、“Contents"というリンクをクリックする動作を考える。
まず、内部テキストが"Contents"である要素を、find_element_by_link_textメソッドでWebElementとして取得する。次に、このWebElementのclick()メソッドを実行する。
例1のスクリプトと合わせると、以下のようになる。
from selenium import webdriver
driver = webdriver.Chrome(executable_path="C:\selenium\chromedriver.exe")
driver.get("https://en.wikipedia.org")
link_ele = driver.find_element_by_link_text("Contents")
link_ele.click()
上記を実行すると、以下のページが開く。 https://en.wikipedia.org/wiki/Wikipedia:Contents
テキストを入力・送信する #
Wikipediaトップページの右上の検索窓に、単語を入力して検索することを考える。 この検索窓のHTML上の情報を調べるため、ブラウザの開発者ツールを用いる。Chromeの場合はF12キーを使用する。
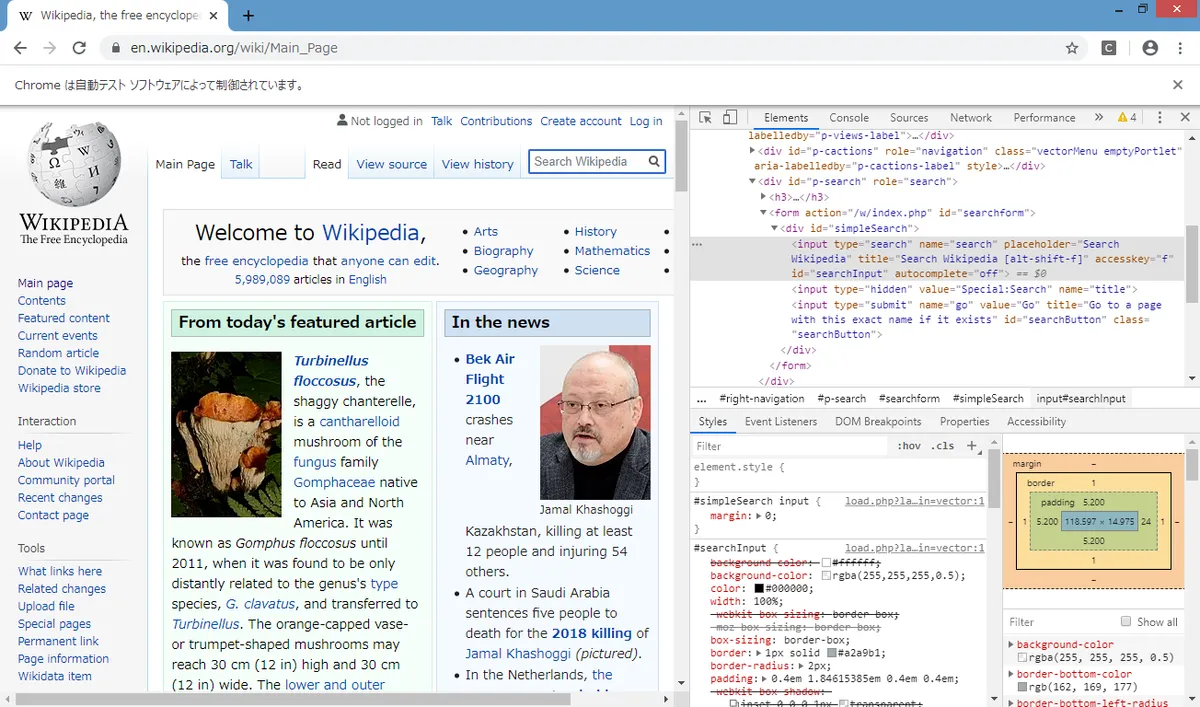
画像右上のHTMLソースの背景が灰色になっている箇所より、検索窓のid属性はsearchInputであることが分かる。これをfind_element_by_idメソッドを使って、WebElementオブジェクトとして取得する。
次に、send_keysメソッドを使って、検索窓に渡したい文字列を指定する。最後にsubmitメソッドを実行すると、「送信」を押したことになり、検索結果のページが得られる。
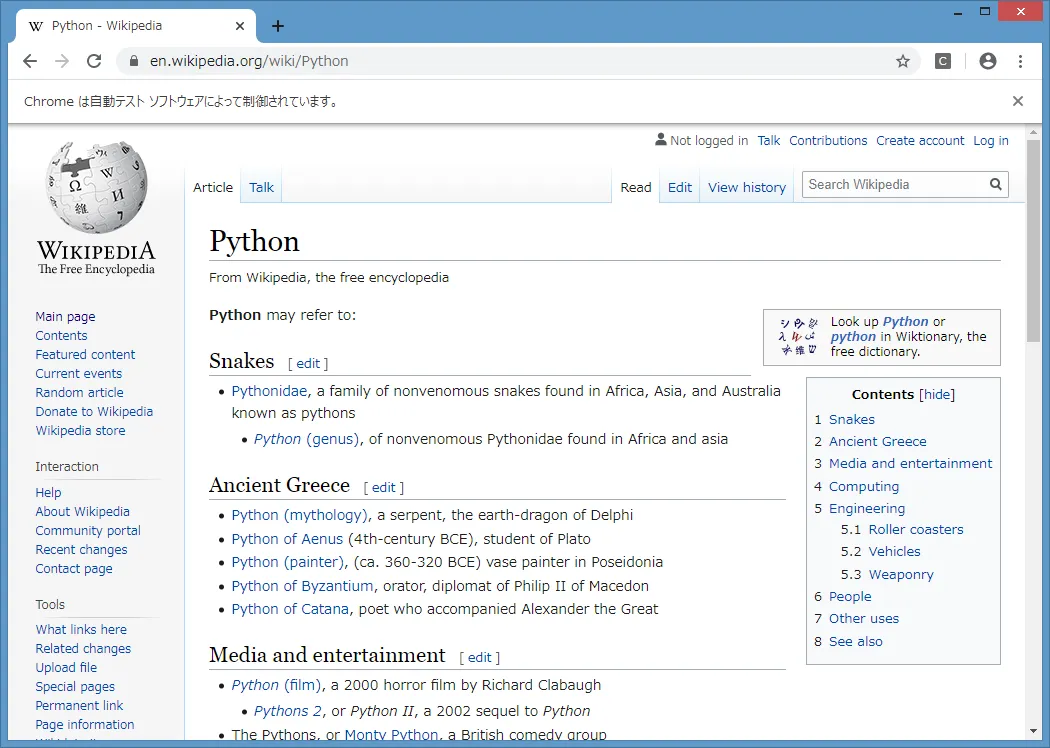
例4 Wikipediaで"python"を検索する。
from selenium import webdriver
driver = webdriver.Chrome(executable_path="C:\selenium\chromedriver.exe")
driver.get("https://en.wikipedia.org")
search_ele = driver.find_element_by_id("searchInput")
search_ele.send_keys("python")
search_ele.submit()
実行結果 以下のページが表示される。