はじめに #
前回、KerasのRecurrentレイヤを使った時系列予測を扱った。
Kerasを使ったRNN, GRU, LSTMによる時系列予測
このとき、Reccurent層に入力するデータを下図のように変形していたが、この方法ではデータサイズが約timesteps倍に増加してしまう。
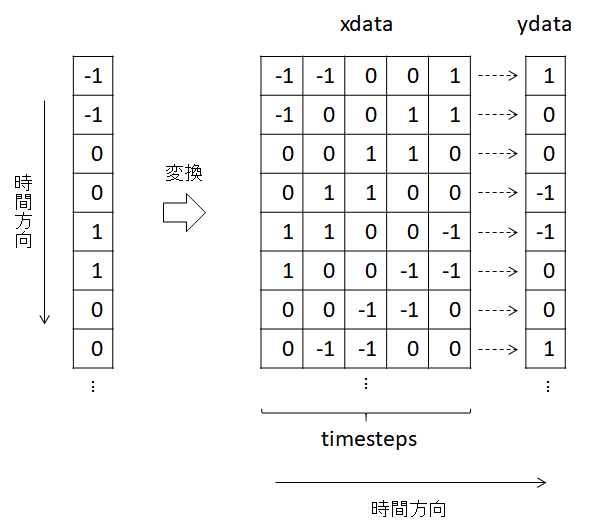
そこで、Pythonのジェネレータ (generator) を使い、データを呼び出すときに必要なデータだけ変形することで、大容量のデータを扱う場合でもメモリが不足しないようにする。 なお、ジェネレータとは、for文などを使って要素を逐次的に出力できるオブジェクトであり、なおかつ、1要素を取り出そうとする度に処理を行うものである。本記事ではジェネレータに関する知識は必要ないが、詳細を知りたい方は以下の記事を参照のこと。 Pythonのイテレータとジェネレータ - Qiita
環境 #
| ソフトウェア | バージョン |
|---|---|
| Anaconda3 | 2019.03 |
| Python | 3.7.3 |
| TensorFlow | 1.13.1 |
| keras | 2.2.4 |
| NumPy | 1.16.2 |
本記事では、Pythonで以下の通りライブラリをインポートしていることを前提とする。
import numpy as np
from keras.utils import Sequence
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN
Sequentialモデルのgeneratorに関するメソッド #
KerasのSequentialモデルには、generatorを使った学習・検証・予測がサポートされている。
学習はfit_generatorメソッド、検証はevaluate_generatorメソッド、予測はpredict_generatorメソッドをそれぞれ用いる。
fit_generatorメソッドとpredict_generatorメソッドについて簡単に解説する。ここでは一部の引数しか記載していないため、全ての引数を知りたい方は以下のページを参考のこと。
Sequentialモデル - Keras Documentation
fit_generatorメソッド #
fit_generator(self, generator, epochs=1,
validation_data=None, shuffle=True)
引数の説明は以下の通り。 generator: 学習データのgeneratorクラス。呼び出す度に(inputs, targets)のタプルを返す。 epochs: エポック数 (int). デフォルト値は1. validation_data: 検証データのgeneratorクラスまたは(inputs, targets)のタプル(任意)。 shuffle: 各試行の初めにバッチの順番をシャッフルするかどうか。デフォルト値はTrue.
predict_generatorメソッド #
predict_generator(self, generator)
引数の説明は以下の通り。 generator: 説明変数を返すgeneratorクラス。
generatorクラスの作成 #
Recurrentレイヤに入力するためのデータを生成するgeneratorクラスを実装する。
genaratorクラスは、keras.utils.Sequence()クラスを基底クラスとする。
また、学習(fit_generatorメソッド)では説明変数と目的変数の両方、予測(predict_generatorメソッド)では説明変数のみ扱うため、それぞれ異なるgeneratorクラスを作る。
学習用generatorクラス #
次のReccurentTrainingGeneratorクラスを実装した。
class ReccurentTrainingGenerator(Sequence):
""" Reccurent レイヤーを訓練するためのデータgeneratorクラス """
def _resetindices(self):
"""バッチとして出力するデータのインデックスを乱数で生成する """
self.num_called = 0 # 同一のエポック内で __getitem__ メソッドが呼び出された回数
all_idx = np.random.permutation(np.arange(self.num_samples))
remain_idx = np.random.choice(np.arange(self.num_samples),
size=(self.steps_per_epoch*self.batch_size-len(all_idx)),
replace=False)
self.indices = np.hstack([all_idx, remain_idx]).reshape(self.steps_per_epoch, self.batch_size)
def __init__(self, x_set, y_set, batch_size, timesteps, delay):
"""
x_set : 説明変数 (データ点数×特徴量数)のNumPy配列
y_set : 目的変数 (データ点数×1)のNumPy配列
batch_size: バッチサイズ
timesteps : どの程度過去からデータをReccurent層に与えるか
delay : 目的変数をどの程度遅らせるか
"""
self.x = np.array(x_set)
self.y = np.array(y_set)
self.batch_size = batch_size
self.steps = timesteps
self.delay = delay
self.num_samples = len(self.x)-timesteps-delay+1
self.steps_per_epoch = int(np.ceil( self.num_samples / float(batch_size)))
self._resetindices()
def __len__(self):
""" 1エポックあたりのステップ数を返す """
return self.steps_per_epoch
def __getitem__(self, idx):
""" データをバッチにまとめて出力する """
indices_temp = self.indices[idx]
batch_x = np.array([self.x[i:i+self.steps] for i in indices_temp])
batch_y = self.y[indices_temp+self.steps+self.delay-1]
if self.num_called==(self.steps_per_epoch-1):
self._resetindices() # 1エポック内の全てのバッチを返すと、データをシャッフルする
else:
self.num_called += 1
return batch_x, batch_y
以下、簡単な解説である。
Kerasの仕様上、Sequenceを継承するクラスは、__len__, __getitem__メソッドを備えなければならない。
__len__メソッドは1エポックで生成するバッチ数を返す。
また、__getitem__メソッドはReccurentTrainingGeneratorクラスを呼び出す度に実行され、説明変数と目的変数をバッチで返す。
__getitem__メソッドで返されるbatch_xとbatch_yのイメージは以下の図の通りである。
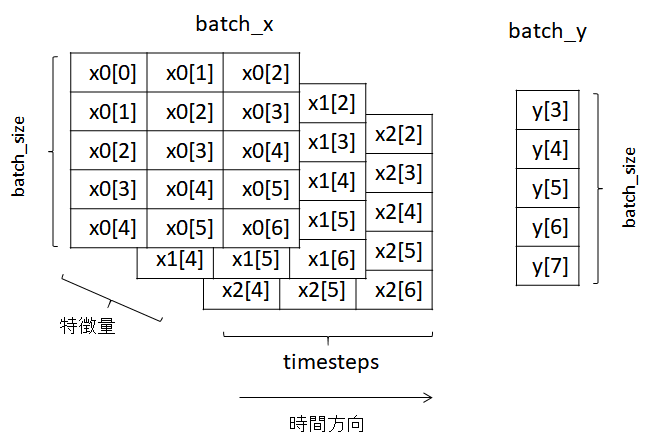
ここで、x1, x2, x3は異なる説明変数であり、括弧内の数字は時刻を示す。
また、batch_sizeは5, timestepsは3, delayは1である。
delayが1とは、時刻tまでのデータを用いて、時刻t+1のデータを予測することを意味する。
batch_xは(バッチサイズ×timesteps×特徴量数)の3次元配列、
batch_yは(バッチサイズ×1)の2次元配列である。
ただし、実際にはバッチ方向の時系列の並びはシャッフルされる。
学習データを格納したReccurentTrainingGeneratorをfit_generatorメソッドに渡してやればよい。
予測用generatorクラス #
次のReccurentPredictingGeneratorクラスを実装した。
class ReccurentPredictingGenerator(Sequence):
""" Reccurent レイヤーで予測するためのデータgeneratorクラス """
def __init__(self, x_set, batch_size, timesteps):
"""
x_set : 説明変数 (データ点数×特徴量数)のNumPy配列
batch_size: バッチサイズ
timesteps : どの程度過去からデータをReccurent層に与えるか
"""
self.x = np.array(x_set)
self.batch_size = batch_size
self.steps = timesteps
self.num_samples = len(self.x)-timesteps+1
self.steps_per_epoch = int(np.floor( self.num_samples / float(batch_size)))
def __len__(self):
""" 1エポックあたりのステップ数を返す """
return self.steps_per_epoch
def __getitem__(self, idx):
""" データをバッチにまとめて出力する """
start_idx = idx*self.batch_size
batch_x = [self.x[start_idx+i : start_idx+i+self.steps] for i in range(self.batch_size)]
return np.array(batch_x)
目的変数を出力せず、データをシャッフルする必要がない以外は、ReccurentTrainingGeneratorクラスと同じである。
__getitem__メソッドでは先程の図のbatch_xのみ返される。
ただし、バッチ方向の時系列の並びはシャッフルされない。
予測用データを格納したReccurentPredictingGeneratorをpredict_generatorメソッドに渡してやればよい。
記事が長くなったため、generatorの使い方は後編に分けた。 Kerasの時系列予測でgeneratorを使って大容量データを扱う 後編
参考 #
今回と次回の記事のコードをまとめたものをGithubにおいている。 https://gist.github.com/helve2017/c20d6106a5dab00a8afa942584b60580
Kerasの公式リファレンス。 Sequentialモデル - Keras Documentation ユーティリティ - Keras Documentation
