はじめに #
KerasのRNN, GRU, LSTMレイヤを使って時系列データを学習させる。Kerasを初めて使われる方は、以下の記事を参考にして下さい。 Keras入門 ニューラルネットワークによる正弦波の回帰
環境 #
| ソフトウェア | バージョン |
|---|---|
| Anaconda3 | 5.2.0 |
| Python | 3.6.5 |
| TensorFlow | 1.12.0 |
| keras | 2.2.4 |
| NumPy | 1.14.3 |
| matplotlib | 2.2.2 |
KerasとTensorFlowがインストールされていなければ、Anaconda Promptで以下の通りインストールする。
conda install tensorflow
conda install keras
次に、Pythonで以下の通りライブラリをインポートする。
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN, GRU, LSTM
Recurrentレイヤ #
Kerasには、いくつかのRecurrent(再帰)レイヤが実装されている。本稿ではRNN, GRU, LSTMを使って、学習速度を簡単に比較する。
RNN (Recurrent Neural Network) は、1ステップ前の出力を自身の入力として与えることで、過去の情報を利用できる。ただし、RNNでは長期間のデータを扱えないため、GRU (Gated Recurrent Unit) やLSTM (Long Short Term Memory) が使われることが多い。 GRUとLSTMは、RNNを改良したレイヤであり、より長期間のデータの依存関係を学習できる。GRUはLSTMに比べて学習パラメータが少なく、計算時間が短い特徴がある。
学習データ #
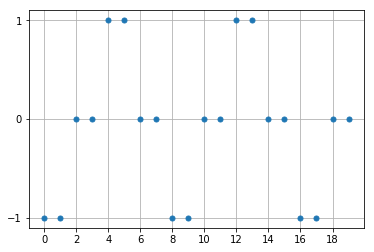
図のように、
[-1, -1, 0, 0, 1, 1, 0, 0, …]
を繰り返す時系列データが与えられたとき、次のステップの値を予測させる。正しく予測するためには、最低でも3個以上の過去のデータを記憶する必要がある。
例えば、[0, 0]とデータが与えられても、次の値は1か-1か分からない。さらに1ステップ前から[-1, 0, 0]と連続して初めて、次の値が1と予測できる。
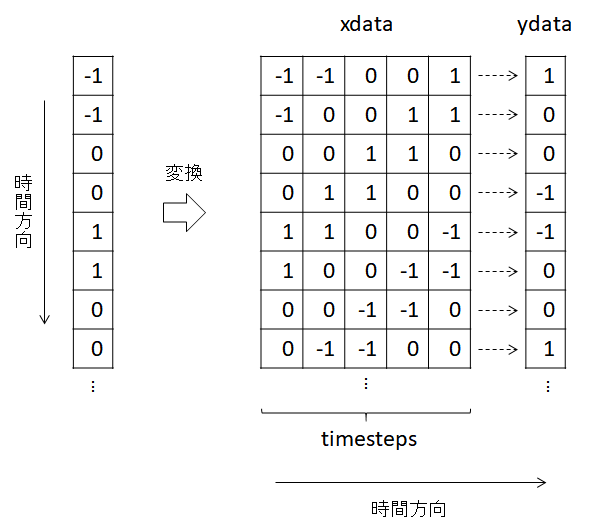
Kerasで学習するためのデータの配列の形状は以下のイメージ。
左側の時系列データを、説明変数xdataと目的変数ydataに変換する。
1個の目的変数に対して、予測に用いるステップ数がtimestepsである。
以下のコードで時系列データの生成と変換を行う。
timesteps = 5
x_base = np.array([-1,-1,0,0,1,1,0,0], dtype=np.float32)
x = np.empty(0, dtype=np.float32)
for i in range(1000):
x = np.hstack([x, x_base])
xdata = np.array([x[i:i+timesteps] for i in range(len(x)-timesteps)])
xdata = xdata.reshape(xdata.shape[0], timesteps, -1)
ydata = x[timesteps:].reshape(xdata.shape[0], -1)
timestepsは5とした。
また、reshapeメソッドを使って、
xdataは(データ数×timesteps×説明変数の数)の3次元配列、
ydataは(データ数×目的変数の数)の2次元配列
にそれぞれ変換している。
kerasによる学習 #
NNモデル #
説明変数と目的変数の次元はともに1なので、入力層と出力層のノード数は1となる。 1層目をRNNレイヤ、2層目を全結合(Dense)レイヤとする。 中間ノード数はそれぞれ10とし、活性化関数はtanhとする。
actfunc = "tanh"
model = Sequential()
model.add(SimpleRNN(10, activation=actfunc,
batch_input_shape=(None, timesteps, 1)))
model.add(Dense(10, activation=actfunc))
model.add(Dense(1))
なお、SimpleRNNレイヤのbatch_input_shapeには、
(バッチ数、学習データのステップ数、説明変数の数)
をタプルで指定する。
バッチ数は学習時に指定するので、ここではNoneとする。
また、GRUレイヤやLSTMレイヤに変更する場合は、以下のようにSimpleRNNをGRU, LSTMに変更するだけでよい。
model.add(GRU(10, activation=actfunc,
batch_input_shape=(None, timesteps, 1)))
model.add(LSTM(10, activation=actfunc,
batch_input_shape=(None, timesteps, 1)))
学習の実行 #
NNモデルにデータを学習させる。PCの性能によるが、数十秒程度で終了する。
model.compile(optimizer='sgd',
loss='mean_squared_error')
history = model.fit(xdata, ydata,
batch_size=100,
epochs=500,
verbose=1)
学習モデルの評価 #
学習したモデルから予測値を出力する(簡単のため、学習データから予測させる)。
pred = model.predict(xdata)
fig, ax = plt.subplots()
ax.plot(ydata[:20, :].reshape(-1), linewidth=0, marker="o", markersize=8)
ax.plot(pred[:20, :].reshape(-1), linewidth=0, marker="o", markersize=5)
ax.set_xticks(np.arange(0, 20, 2))
ax.set_yticks([-1, 0, 1])
ax.legend(["training", "prediction"])
ax.grid()
plt.show()
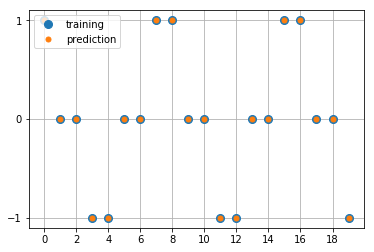
出力
学習データと予測値の最初の20点を比較する(予測値はRNNで学習したモデルから出力したもの)。学習データと予測値は一致しており、うまく学習できたことが分かる。
次に、RNN, GRU, LSTMの損失関数の変化を比較する。損失関数の履歴は、historyから次のように取得できる。
loss = history.history["loss"]
各モデルの損失関数の変化をプロットする。
fig, ax = plt.subplots()
ax.plot(loss_rnn)
ax.plot(loss_gru)
ax.plot(loss_lstm)
ax.legend(["RNN", "GRU", "LSTM"])
plt.show()
出力
縦軸が損失関数、横軸がエポック数である。RNN, GRU, LSTMの順に損失関数の減少が速い。実際、各レイヤの学習パラメータはこの順に多くなっており、今回の学習速度と比較して妥当な結果である。
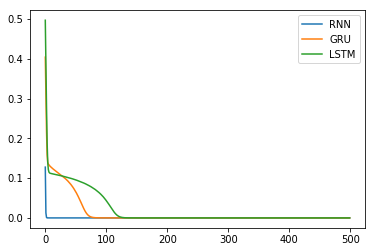
※今回の学習データではRNNでも十分に精度の高い予測ができたが、当然、学習パラメータが多いほどレイヤの表現力が高いため、より複雑な時系列データの特徴を抽出できる可能性が高い。
参考 #
Recurrentレイヤー - Keras Documentation 再帰型ニューラルネットワーク: RNN入門 - Qiita 初心者のRNN(LSTM) | Kerasで試してみる - Qiita
